El código genético es la relación entre la secuencia de nucleótidos del ARNm y la secuencia de aminoácidos de una proteína.
La conexión que se establece es a través de secuencias de tres bases del ARNm, conocida como codón, las cuales van a ser reconocidas por el anticodón, otra secuencia de 3 bases complementarias, pero del ARNt.
Así, el ARNt tiene un aminoácido específico para esa secuencia, produciéndose, así, el vínculo entre el codón del ARNm y el aminoácido específico.
Existen 61 codones codificadores de aminoácidos y tres que señalan el final del mensaje y no especifican ningún aminoácido (UAA, UAG y UGA). Por su parte, el codón AUG, además de codificar para metionina, es la señal de comienzo de la síntesis.
Este código genético presenta algunas características como:
- Es universal: es el mismo para todas las células de todas las especies y ha permanecido invariable a lo largo de miles de millones de años de evolución. Solo se han encontrado excepciones a esta universalidad en las mitocondrias, en algunos protistas ciliados y en micoplasmas.
- Es degenerado: un aminoácido puede estar codificado por más de un codón.
- Específico: ningún codón codifica más de un aminoácido.
- No hay espacios, separaciones o solapamientos entre los sucesivos codones.
Con todo ello, el código genético viene indicado en la siguiente tabla:

Código genético. En esta tabla se puede encontrar la equivalencia entre las secuencias de 3 bases nitrogenadas del ARNm (codón) y el aminoácido específico para esa secuencia.
RESOLUCIÓN DE PROBLEMAS PRÁCTICOS DE REPLICACIÓN
Aunque la mayoría de preguntas de la replicación suelen estar relacionadas con la teoría, bastando el respectivo estudio de la entrada específica de la Replicación en este blog para su correcto desempeño, puede haber problemas prácticos en los que es necesario conocer los siguientes puntos:
- Las cadenas de ADN son antiparalelas, es decir, el extremo 5´de una de ellas se opone al extremo de 3´de la complementaria.
- Ambas hebras son complementarias, es decir, sus bases nitrogenadas se aparean en función a la siguiente relación:
- Adenina empareja con Timina y viceversa.
- Guanina empareja con Citosina y al revés.
Con ello, imaginemos el siguiente problema, si la hebra codificante de un oligonucleótido de DNA es la siguiente:
5’ – ATTAGCCGAATGATT – 3’
¿Cuál es la secuencia de su complementaria?
Teniendo en consideración lo expuesto anteriormente, desarrollaremos una hebra orientada de 3´a 5´, ya que ambas cadenas son antiparalelas, siguiendo la complementariedad y equivalencia de las bases citada.
Cadena que nos dan → 5’ – A T T A G C C G A A T G A T T – 3’
Cadena que nos piden→ 3´– T A A T C G G C T T A C T A A – 5´
RESOLUCIÓN DE PROBLEMAS PRÁCTICOS DE TRANSCRIPCIÓN
Como vimos en otras entradas del blog, la transcripción es el paso de la información genética respectiva a un gen o conjunto de genes de ADN a ARN mensajero (ARNm). Por consiguiente, traspasamos un código de desoxirribonucleótidos a ribonucleótidos.
Asimismo, debemos de tener en cuenta lo siguiente:
- Solo se transcribe una de las dos cadenas de ADN, la denominada hebra molde, con sentido o no codificante. La hebra codificante o sin sentido no se transcribe.
- Una vez que sabemos cuál es la hebra molde, transcribiremos la información teniendo en cuenta que ambas cadenas son antiparalelas, es decir, que el extremo 5´ del ADN se opone al 3´del ARNm.
- Al estar hablando de ribonucleótidos, la complementariedad es la siguiente:
- Adenina empareja con Uracilo y viceversa. Esta es la diferencia notable, no sabéis cuantos exámenes he corregido con este fallo.
- Citosina se complementa con Guanina y su inverso, es decir, como el caso del ADN.
Una vez expuestas las bases para el correcto desempeño de los ejercicios, intentemos resolver el siguiente problema, observa el siguiente segmento de ADN:
5’ G C T T C C C A A 3’
3’ C G A A G G G T T 5’
a) Escribe la molécula de ARN que se transcribiría a partir de este segmento. Considera que la ARN polimerasa usa la hebra superior como molde cuando va a sintetizar ARN.
Ya sabemos cuál es la cadena molde, puesto que nos dice que la ARN polimerasa utiliza la «hebra superior» como tal. Por consiguiente, vamos a realizar la complementaria, en forma de ARN de la cadena de ADN orientada de 5´→3´:
ADN: 5’ G C T T C C C A A 3’
ARN: 3´ C G A A G G G U U 5´
A mí, personalmente, me gusta ordenar el ARNm que transcribo en posición 5´→3´, porque luego, normalmente, siempre te hacen preguntas sobre la traducción, pasando dicho código de ARN al de aminoácidos. Por ello, al orientarlo como menciono, ya lo tenemos ordenado para la equivalencia entre codones y aminoácidos, si no habría que leerlo al revés.
Además, lo correcto sería disponerlo como digo, ya que, como recordaréis, la ARN Polimerasa lee la cadena molde de ADN en sentido 3´→5´, sintetizando ese ARNm con orientación 5´→3´.
Así quedaría: 5’ U U G G G A A G C 3’
RESOLUCIÓN DE PROBLEMAS PRÁCTICOS DE TRADUCCIÓN
La traducción es el paso de la secuencia de bases del ARN mensajero (ARNm) a la cadena de aminoácidos integrantes de los péptidos o proteínas.
Aunque también hay preguntas teóricas que serían fáciles si nos basamos en la información depositada en la respectiva entrada del Blog, suelen hacer problemas relacionados con un aspecto más práctico que suelen dar lata. Por ello, debemos de tener en mente lo siguiente:
- La equivalencia entre las bases de ARNm y la secuencia de aminoácidos se realiza a través de conjuntos de tres bases nitrogenadas conocidos como codón.
- Los codones del ARNm son leídos de dirección 5´→3´. Por eso os dije que en los problemas de transcripción era mejor que orientarais así la cadena.
- La secuencia de aminoácidos se crea desde el extremo N-terminal (amino) hasta el C-terminal (carboxilo). Es decir, el primer codón leído, el posicionado en el extremo 5´se corresponde con el aminoácido del extremo N-terminal de la proteína.
- Para saber dicha equivalencia es necesario recurrir a tablas como la que aparece más arriba en esta entrada, aunque también nos pueden dar la información en forma más esquemática y compleja, como esta:
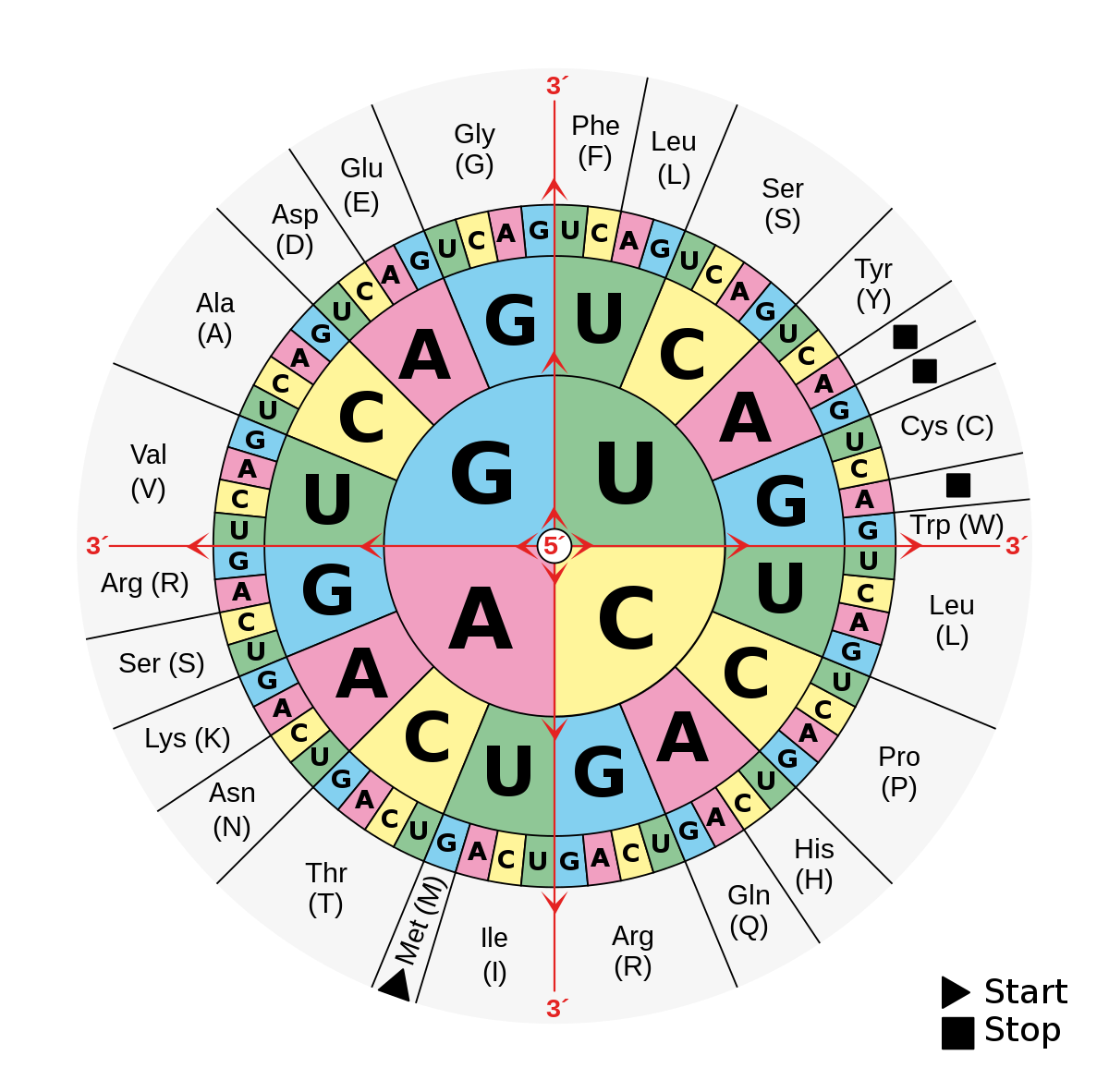
Código genético. Como podéis ver, este tipo de diagrama es más complejo. Para su interpretación debemos de leerlo del interior hacia el exterior. Así, como sabéis, leemos el codón de 5´a 3´. Por ejemplo, si cogemos la letra G (la del centro), con la A (en el medio) y la C (en amarillo, al final y pequeña), tenemos el codón GAC, que corresponde con el aminoácido Aspartato (Asp-D).
- Como encontráis en el diagrama y en la tabla superior, el codón AUG corresponde, además de la Metionina, a la secuencia de iniciación; mientras que los codones UAA, UAG y UGA indican una secuencia de terminación.
Ahora, con estas nociones básicas, vamos a realizar el siguiente problema:
Un fragmento de ADN presenta la siguiente secuencia de bases:
5’… TTCGTTACACCCGCCTCTGGTGCA…3’
3´… AAGCAATGTGGGCGGAGACCACGT… 5´
Utilizando como molde la hebra correspondiente, tras su expresión da lugar a un fragmento de proteína con la siguiente secuencia de aminoácidos:
N-terminal- Phe-Val-Thr-Pro-Ala-Ser-Gly-Ala- C-terminal
a) ¿Cuál sería el fragmento correspondiente al ARN mensajero?
El primer aminoácido, es decir, el del extremo N-terminal es la Fenilalanina (Phe), que según el código genético que aparece más arriba, corresponde a los siguientes codones en forma de ARNm: UUU o UUC.
¿Ahora bien, qué cadena de ADN debo de seleccionar?
Sé que debo encontrar una secuencia de ARNm en cuyo extremo 5´se encuentre la secuencia UUU o UUC, por consiguiente, vamos a transcribir ambas hebras y a ver qué nos encontramos:
1ª PRUEBA
- 1ª Cadena de ADN: 5’… TTC GTT ACA CCC GCC TCT GGT GCA…3’
- Cadena de ARNm complementaria: 3´…AAG CAA UGU GGG CGG AGA CCA CGU…5´
2ª PRUEBA
- 2ª Cadena de ADN: 3´… AAG CAA TGT GGG CGG AGA CCA CGT… 5´
- Cadena de ARNm complementaria: 5’… UUC GUU ACA CCC GCC UCU GGU GCA…3’
¿QUÉ CADENA ELIJO?
Con base en la transcripción, puedo observar que, leyendo el ARNm transcrito de 5´→3´, solo hallo el codón UUC teniendo como molde la segunda cadena de ADN. Por consiguiente, contestando a la pregunta, el segmento correspondiente al ARNm es:
5’… UUC GUU ACA CCC GCC UCU GGU GCA…3’
b) ¿Cuál será el codón de la prolina (Pro)? ¿y en el caso de la alanina (Ala)? Razone la respuesta
Sabemos que la secuencia del ARNm es leída en dirección 5´→3´ para el proceso de la traducción. Por consiguiente, el primer aminoácido de la secuencia propuesta corresponde al primer codón (secuencia de 3 bases) del ARNm dilucidado, es decir, la Phe corresponde con el UUC.
Consecutivamente, el extremo 5´ del ARNm coincide con el N-terminal de la proteína y el extremo 3´con el C-terminal.
Con ello, tendríamos lo siguiente:
5’… UUC GUU ACA CCC GCC UCU GGU GCA…3’
Nt…. Phe – Val – Thr – Pro – Ala – Ser – Gly – Ala…Ct
El codón de la Pro (Prolina) sería el CCC, mientras que el de la Alanina sería el GCC y la GCA.
Además, si queréis saber si el ejercicio lo habéis hecho bien, podéis consultarlo en la tabla del código genético que os daría el ejercicio que, como veis, coincide.
El razonamiento de la respuesta aparece en la explicación dada anteriormente, aunque podéis añadir que la equivalencia la hacéis siguiendo las características del código genético, es decir, que la secuencia de tres bases del ARNm equivale a un único aminoácido y que no hay espacios, separaciones ni solapamientos entre los sucesivos codones. Además, la Alamina puede venir dada por dos codones diferentes, puesto que el código genético es degenerado.
EJERCICIO RESUELTO PASO A PASO
Sé que estos ejercicios suelen costar bastante, así que he resuelto un problema modelo que engloba replicación, transcripción y traducción en el siguiente vídeo: